
(04.06.2020) Antibes, France
We can’t help it. At Ceetron, as soon as we have an SDK, we use it to build our own applications… something like the laws of Nature. This time it’s about the DataProvider Framework – the developers tell me it looks like an SDK, smells like an SDK, but it’s not an SDK (?!). This piece of software defines a clear-cut interface that allows our partners to write custom code to feed our visualization SDKs. Isn’t that a reader ? Well, not exactly… data can of course be brought into the system from a file, but the DataProvider framework also allows to provide data at runtime, from memory (think a running solver).

Anyhow, that’s not really the purpose of this blog. Luis – our most recent whizz developer in our Sophia Antipolis office – has shown his optimization talent when he was asked to develop a DataProvider that reads openFOAM files. We already supported this format as most industry-standard files, but weren’t too happy with performance although we were on a par with Paraview, the natural post-processor for openFOAM simulations… and our friends at SimScale shared this frustration.
That’s where Luis came into action. A few weeks of sweat and indecent quantities of coffee taken at even more indecent nightly hours, and the result is …. spectacular. A detailed report shows the gain we achieved through (his) pain.
We will first thank PiQ2 for sharing models for these tests.
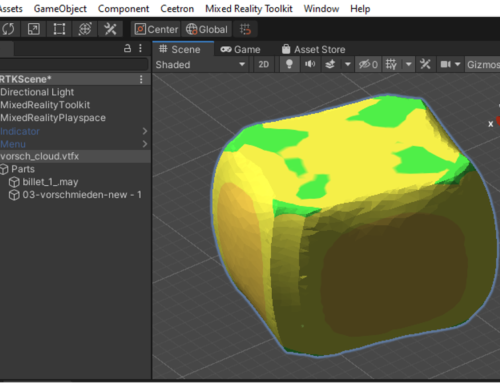
The first test suite is performed on the model above – 1 million+ nodes and almost 1 million elements. We have tested result load times on the entire model and including an isovolume, as well as producing an animation of the die filling. By the way, the “figure” above is a fully interactive 3D model…. Feel free to interact with it. For more info, you can also take a look at it on the portal that hosts it.
Ceetron’s code is two to three times faster than Paraview on these tests. Memory usage is always leaner as well, especially for the animation test (3 times less memory).
On a smaller second confidential PiQ2 casting example (~700 thousand nodes and ~500 thousand elements), the same observations are reproduced. State loading is two to three times as fast, and memory usage is reduced by 25% on average.
Finally, Luis put his code to the test on a larger model – courtesy of Simscale this time. The beast has 15 million+ nodes and 12 million+ elements. But that’s not all: it is also made up of 882 parts. Here we focused on the time in between the moment you click “open” until the model appears in your application. The figure below summarizes the measured times : mesh reading is ~2x faster, and result loading is here a spectacular 10x quicker… Beep ! Beep !

Of course, the number of tests and datasets is limited but the results have been consistent throughout the development stage. And of course, a wider evaluation of the DataProvider couldn’t hurt. Although the performance is impressive, all developers know that the war is never completely won. We hope our partners and prospects will continue to do what they do best : challenge us for performance. We love it..
Be our guest and include the plugin in your applications : Ceetron DataProvider Plugins 1.2.0 or simply try it out with an evaluation of Ceetron Analyzer Desktop
Andres, CSMO




Leave A Comment
You must be logged in to post a comment.